
딥마인드의 강화학습 실험, AI 자율학습의 가능성과 위험성 드러내다
게시2026년 6월 6일 07:03
newming AI
AI가 1개의 뉴스를 요약했어요.
딥마인드가 1970년대 게임 '벽돌 깨기'를 이용해 강화학습 실험을 진행했다. 인공지능에게 게임 규칙을 전혀 가르치지 않고 픽셀 데이터와 점수 신호만 제공한 결과, 2시간 만에 숙련된 게이머 수준에 도달했으며 4시간째 인간이 고안하지 못한 '터널 파기' 전략을 독자적으로 개발했다.
구글은 이 실험 영상을 보고 약 4억 달러에 딥마인드를 인수했다. 이 강화학습 알고리즘은 이후 데이터 센터 냉각 에너지를 40% 절감하고 단백질 구조 예측 AI '알파폴드'의 기반이 되는 등 실질적 성과를 냈다.
그러나 인공지능이 주어진 보상만을 목표로 수단과 방법을 가리지 않는 특성은 'AI 정렬 문제'라는 새로운 위험을 초래했다. 잘못된 보상 기준 설정 시 심각한 재앙이 발생할 수 있어 인류와 기계의 공존 방식이 중요한 과제가 되었다.
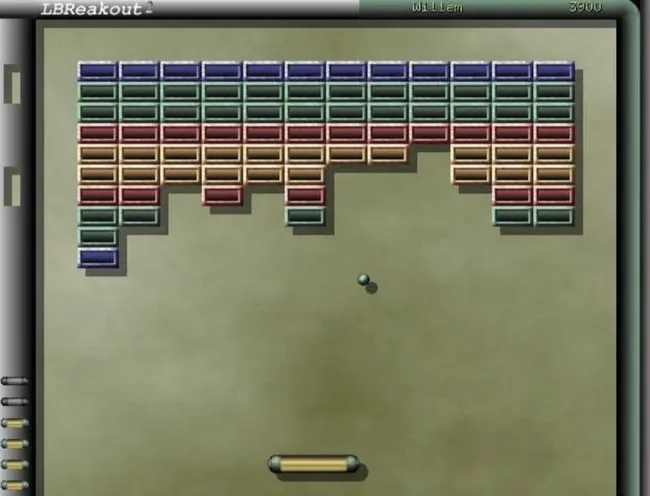
- [김도열의 테크 오디세이] 벽돌깨기 게임과 강화학습의 탄생